재식별 위험
가장 확실한 정보보호는 정보를 아예 공개하지 않는 것입니다. 그렇게 되면 그 정보의 활용 가치 또한 없는 셈입니다. 정보의 활용을 통해 가치를 조금이라도 만들어 보고자 한다면 정보의 공개는 피할 수 없습니다.
정보를 공개하면 재식별의 위험이 발생합니다. 식별자를 제거하더라도 마찬가지입니다. 이것은 근원적인 문제이며 위험의 정도가 달라질 뿐입니다.
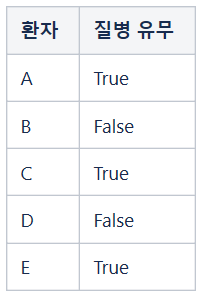
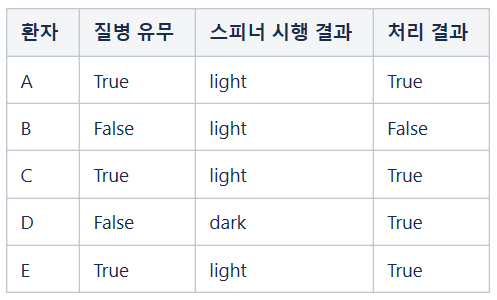
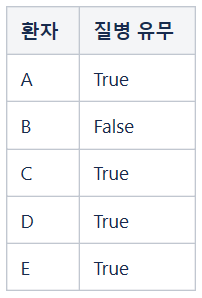
예를 들어, 어떤 지역에 거주하는 사람들 전체를 대상으로 질의 방식을 채택하여 특정 질병 보유 현황을 조사하는 상황을 상상해 봅시다. 조사 기관은 결과를 취합하여 1%에 해당하는 사람들이 해당 질병을 보유하고 있다고 발표하였습니다. 1년 후 동일한 조사를 실시하고 얻은 결과는 1.09%였습니다. 그런데 1년 동안의 전출입 자료에 접근할 수 있는 담당자가 있다면 그는 지난해 총 거주자 수가 1,000 명이었는데 전출자는 없고 전입자만 10명이었다는 사실을 토대로 새로 전입한 열 명 중 한 명이 해당 질병 보유자일 가능성이 높다고 추정할 수 있습니다. 여기서 추정이라고 표현한 이유는 조사 대상자 중 일부가 거짓으로 답변했을 수도 있기 때문입니다.
계산 과정:
- 1,000 명의 1%: 10명
- 1,010 명의 1.09%: 11명
- 전출자는 없으므로 새로 전입한 열 명 중 한 명이 질병 보유자
새로 전입한 열 명 중에 정말로 질병 보유자가 한 명이 포함되어 있다면 그는 10%의 확률로 식별될 가능성이 있으므로 이러한 상황을 알아채는 순간부터 상당한 불안을 느낄 수 있습니다.
위험의 정량화
정보를 공개하는 개인이 재식별 위험으로 인해 느끼는 불안의 정도를 어떻게 정량적으로 다룰 수 있을까요?
조사 대상군에 추가되는 한 개인의 입장에서 생각해 봅시다. 자신의 정보가 추가됨으로 인해 전체 결과에 큰 차이가 난다면 식별 가능성이 높은 것이고 그렇지 않다면 식별 가능성이 낮은 것입니다. 이로부터 개인의 정보가 추가되기 전과 후의 전체 결과의 차이가 개인의 식별 위험의 정도와 관련이 있음을 알 수 있습니다.
- 입력1 -> 처리 알고리즘 -> 출력1
- 입력2 -> 처리 알고리즘 -> 출력2
여기서,
- 입력1: N 명 정보의 데이터베이스
- 입력2: 입력1에 한 명의 정보를 추가한 데이터베이스
위에서 한 명의 정보가 추가됨으로써 발생하는 출력의 차이를 줄일 수 있다면 재식별의 위험을 낮출 수 있습니다. 이를 위해 처리 알고리즘이 제공해야 할 기능은 다음과 같습니다.
- 결과의 차이를 미리 설정한 수준 이하로 유지
이제 결과의 차이를 어떻게 정의하느냐의 문제가 남았습니다.
다시 한 개인의 입장으로 이 문제를 바라봅시다. 예, 아니오와 같은 단답형 질의에 응답할 때 진짜 값을 입력이라고 하면 어떤 확률을 적용하여 진실을 말하거나 거짓을 말하는 것입니다. 진실을 말하는 확률이 1.0에 가까울수록 한 개인의 데이터 차이가 결과 차이로 이어질 가능성이 높고 진실을 말하는 확률이 0.5에 가까울수록 개인의 데이터 차이가 결과 차이로 이어질 가능성이 낮습니다. 확률을 도입하는 것이므로 개별 사건의 결과보다는 기댓값에 초점을 맞추어 살펴보는 것이 이해에 도움됩니다.
이로부터 응답이 참으로 나온 경우 입력이 참인 경우로부터 나왔을 수도 있고 입력이 거짓인 경우로부터 나왔을 수도 있습니다. 만약에 두 가지 가능성의 비율이 크다면, 즉,
의 값이 크다면 더 높은 확률로 대상자의 응답이 참일 가능성이 높은 것이 됩니다. 반면에 두 확률의 비율이 1에 가깝다면 대상자의 응답이 참일 가능성, 거짓일 가능성이 비슷해집니다. 전자의 경우에는 재식별 위험이 높아지고, 후자의 경우에는 재식별 가능성이 낮아지는 상황입니다.
이러한 논의로부터 재식별 위험의 정도를 어떻게 정량화할 것인지에 대한 단서를 찾을 수 있습니다.
Written with StackEdit.